How do Web Browsers Work?
Today, it’s nearly impossible to imagine a world without the internet. And the browser is our interface to the Web. It handles the retrieval, presentation, and traversal of this content. I think we all take for granted that when we push enter in our browsers address bar, magic happens.
But do you have any idea how this actually works? How does it turn a string of HTML into a data structure? Where do CSS & JavaScript come into play?
The main components of modern web browsers can be broken down into the following areas:
FETCH
Network Layer: responsible for fetching data from the relevant web servers. The networking layer accepts URLs via the address bar and fetches resources via HTTP/FTP protocols. Once the resource is returned, this layer feeds the data to our rendering engine. The networking layer plays a major role in our user experience as it can be a bottleneck in web performance as we wait for the requested remote content.
PROCESS
The processing phase accepts the data from our network layer and feeds our display subsystems.
Rendering Engine: responsible for actually displaying the web page. Rendering engines parse the HTML & CSS and display that parsed content to you.
The browsers HTML parser converts HTML elements into DOM nodes in a tree called the content tree. Meanwhile the CSS parser is parsing our stylesheets and inline style elements to generate the pages style rules. This style information is combined with the visual instructions from our HTML and are used to create another tree — the render tree.
This render tree is then exposed to our JS. And finally once the render tree is constructed, it undergoes layout and painting processes, and the output is displayed on the screen.
As an aside, if you’ve ever wondered why Chrome obliterates your RAM, it’s because the Chrome browser actually runs multiple instances of the rendering engine: 1 for each tab.

JavaScript Engine: responsible for reading and executing our Javascript code. Engines are the ones that actually have to implement the ECMAScript standards defined by the TC39 committee (without this, JavaScript would just be a bunch of weird curly brackets and semicolons).
So what does the engine actually do? It parses our Javascript code to machine code and then executes it.
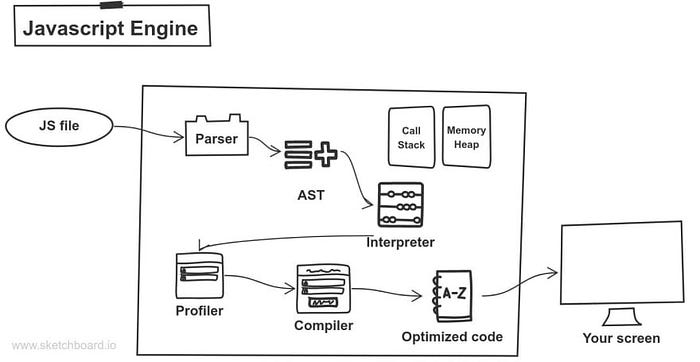
Our engine first parses our file and generates nodes based on the tokens received. With these nodes, the Abstract Syntax Tree (AST) is created.
Next in the flow is the interpreter, it analyzes the AST and generates byte code. The interpreter produces unoptimized machine code quickly and can start running without delay. The profiler is assessing this code as it runs and looking for areas to optimize.
With the support of the profiler, any unoptimized code is passed to the compiler to perform enhancements and produce machine code that ultimately replaces its equivalent in the previously created unoptimized code by the interpreter.
A note on the compilation phase, JS being dynamically typed makes our lives as developers simpler as we don’t have to worry about types. But if you’re a compiler, this is bad news because we’re not giving it much to go on and that makes it extremely difficult to generate machine code that’s fast. Our JS engines work around this by employing just-in-time (JIT) compilation which enables them to optimize performance. (All JIT means is the compiler will generate machine code during runtime, not ahead of time).
Most modern engines have at least 2 compilers, with 1 of them being an optimizing compiler. This is done by re-compiling “hot” (functions that you’re using a lot and as a result worth speeding up) functions with type information from the previous execution. If at some point the type has changed will de-optimize and fall back to the baseline compiler.
UI Backend: used for drawing basic widgets like combo boxes, popups, and alerts. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
Display
The user interface and browser engine are responsible for presenting all this data to the user.
User Interface: this includes things like the address bar, forward/back/refresh buttons, favorites menu, etc. Essentially everything you see except the web page itself. Browser user interfaces have a lot in common with each other, despite the fact that there is actually no specific standards on how the UI should look.
Browser Engine: handles interactions between the UI and the rendering engine. The engine supports the basic browsing actions such as navigating forward, back and reload.
Storage
Data Storage: this is a persistence layer. This is achieved through various browser APIs. Some of these include: Local Storage, Session Storage, Cookies, WebSQL, IndexedDB, FileSystem, AppCache.
Wrapping Up
Hopefully you now have a bit more of a grasp on what’s happening under the hood and can appreciate that browsers are actually one of the most complex applications that we use on a daily basis.
Additional Resources:
